Thấy bài hay về AI có ích cho dân SEO em lại share nha…
So với CoT ngắn, CoT dài hiệu quả hơn cho các tác vụ suy luận phức tạp và mở rộng tốt hơn khi dùng supervised fine-tuning (SFT) và reinforcement learning (RL), dẫn đến khả năng tổng quát hóa tốt hơn.
Dùng CoT dài để scaling inference compute hỗ trợ tốt các hành vi như backtracking và sửa lỗi, chia nhỏ các bước khó và cải thiện liên tục các cách tiếp cận thay thế, từ đó dẫn đến các quá trình suy luận có cấu trúc hơn.
CoT DÀI LÀ GÌ?
CoT dài là độ dài của chuỗi các token suy luận (extended sequence of reasoning tokens) thể hiện các hành vi phức tạp vượt quá độ dài token thông thường. Những hành vi này bao gồm:
-
Phân nhánh và Quay lui (Branching and Backtracking): Mô hình khám phá một cách có hệ thống nhiều hướng đi (phân nhánh) và quay trở lại các điểm trước đó nếu một hướng đi cụ thể được chứng minh là sai (quay lui).
-
Xác thực và Sửa lỗi: Mô hình phát hiện sự không nhất quán hoặc sai sót trong các bước trung gian của nó và thực hiện các hành động sửa chữa để khôi phục tính mạch lạc và độ chính xác.
So sánh CoT ngắn với CoT dài
Độ phức tạp của suy luận:
-
CoT Ngắn: Hiệu quả đối với các vấn đề đơn giản nhưng có thể bị hạn chế đối với các nhiệm vụ phức tạp đòi hỏi phân tích sâu.
-
CoT Dài: Giúp giải quyết các vấn đề phức tạp bằng cách chia chúng thành các bước nhỏ hơn và đưa reflection vào quá trình giải quyết vấn đề, dẫn đến các giải pháp chính xác và toàn diện hơn.
Độ dài token và chiều sâu:
- CoT Dài: Đặc trưng bởi một chuỗi token suy luận mở rộng, không chỉ có độ dài token lớn hơn bình thường mà còn thể hiện các hành vi cao cấp như phân nhánh, quay lui, xác thực lỗi và sửa lỗi.
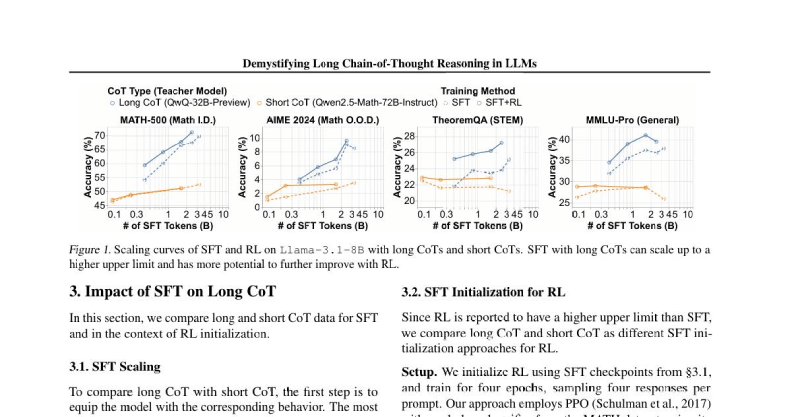
Khả năng mở rộng SFT:
-
CoT Ngắn: SFT có mức độ chính xác thấp hơn và nhanh bão hòa (độ chính xác không tăng dù tăng dữ liệu).
-
CoT Dài: SFT tiếp tục cải thiện độ chính xác của mô hình khi tăng dữ liệu training, đạt đến giới hạn hiệu suất cao hơn so với CoT ngắn.
Cải thiện RL:
-
CoT Ngắn: Các mô hình dùng CoT ngắn khi SFT thu được ít lợi ích từ RL.
-
CoT Dài: Dùng CoT dài khi SFT giúp cải thiện RL tốt hơn. Ví dụ, trên MATH-500, RL có thể cải thiện 3% các mô hình SFT CoT dài, trong khi các mô hình SFT CoT ngắn có độ chính xác gần như tương đương trước và sau RL.
Khả năng tổng quát hóa và lợi ích RL:
-
CoT Ngắn: Không tổng quát hóa tốt bằng CoT dài và thu được lợi ích nhỏ hơn từ RL.
-
CoT Dài: Các patterns CoT dài chất lượng cao, có tính đột sinh (emergent) giúp khả năng tổng quát hóa và lợi ích RL tốt hơn đáng kể. Các mô hình được huấn luyện với emergent long CoT pattern đạt được độ chính xác cao hơn đáng kể trên các bài kiểm tra OOD (ngoài phân phối).
Làm thế nào để tạo ra CoT dài?
-
SFT: SFT có thể đơn giản hóa việc huấn luyện và cải thiện hiệu quả. SFT dùng CoT dài giúp các mô hình đạt được hiệu suất cao hơn và tạo điều kiện cho việc cải thiện RL dễ dàng hơn. Các long CoT patterns có chất lượng cao và đột sinh (emergent) trong SFT dẫn đến khả năng tổng quát hóa tốt hơn và thu được nhiều lợi ích từ RL hơn.
-
Tính toán huấn luyện và Định hình phần thưởng (Training Compute and Reward Shaping): Khả năng suy luận có xu hướng xuất hiện khi tăng tính toán huấn luyện. Định hình phần thưởng rất quan trọng để ổn định việc tăng độ dài cho CoT. Dùng cosine length-scaling reward làm hàm phần thưởng để ổn định sự phát triển của CoT và khuyến khích phân nhánh và quay lui.
-
Tín hiệu phần thưởng có thể xác minh (Verifiable Reward Signals): Scaling verifiable reward signals có vai trò rất quan trọng đối với RL. Trong RL, reward signals là phản hồi cho hành động của agent để giúp nó cải thiện hiệu suất làm việc. Dùng dữ liệu web nhiễu (chất lượng kém) kết hợp với cơ chế lọc nhiễu cho thấy tiềm năng tốt, đặc biệt đối với các tác vụ ngoài phân phối (OOD) như suy luận STEM. Thêm dữ liệu nhiễu nhưng đa dạng vào SFT dẫn đến hiệu suất ổn định trên các tác vụ khác nhau. Để thu được tín hiệu phần thưởng từ noisy verifiable data, rule-based verifier hoạt động tốt nhất sau khi chọn lọc prompt cho các câu trả lời dạng ngắn.
-
Dùng RL để Kích thích kỹ năng: Các kỹ năng cốt lõi như phân nhánh và xác thực lỗi vốn đã có trong các base models, nhưng việc khuyến khích các kỹ năng này một cách hiệu quả thông qua RL đòi hỏi thiết kế cẩn thận và nguồn lực tính toán đáng kể.
-
Điều chỉnh Cosine Reward: Cosine Reward có thể được điều chỉnh để khuyến khích các hành vi mở rộng độ dài khác nhau.
-
Kích thước cửa sổ ngữ cảnh: Các mô hình có thể cần nhiều mẫu huấn luyện hơn để tận dụng tối đa kích thước cửa sổ ngữ cảnh lớn hơn.
-
Giảm thiểu hành vi Reward Hacking: Phần thưởng khuyến khích độ dài của CoT có thể bị hack (tăng độ dài vô tội vạ để nhận thưởng) nếu agent được cung cấp đủ tài nguyên tính toán, nhưng có thể hạn chế hành vi này bằng cách sử dụng repetition penalty (phạt nếu tiếp tục hack).
-
Dữ liệu tiền huấn luyện (pre-training): RL chủ yếu hướng dẫn mô hình kết hợp lại các kỹ năng mà nó đã tiếp thu trong quá trình tiền huấn luyện thành các hành vi mới để cải thiện hiệu suất trong việc giải quyết vấn đề phức tạp.

Bài của Facebook Hoàng Dũng AI