Trạng thái “Crawled - Currently Not Indexed” hoặc tiếng Việt là “Đã thu thập - hiện tại chưa được lập chỉ mục” trong Google Search Console nghĩa là Google đã thu thập dữ liệu trang của bạn nhưng chưa thêm nó vào chỉ mục tìm kiếm. Do đó, trang sẽ không xuất hiện trong kết quả tìm kiếm. Đây là một vấn đề phổ biến đối với các trang mới hoặc ít quan trọng, nhưng việc giải quyết nó có thể cải thiện đáng kể khả năng index để hiển thị cho người dùng tìm kiếm.
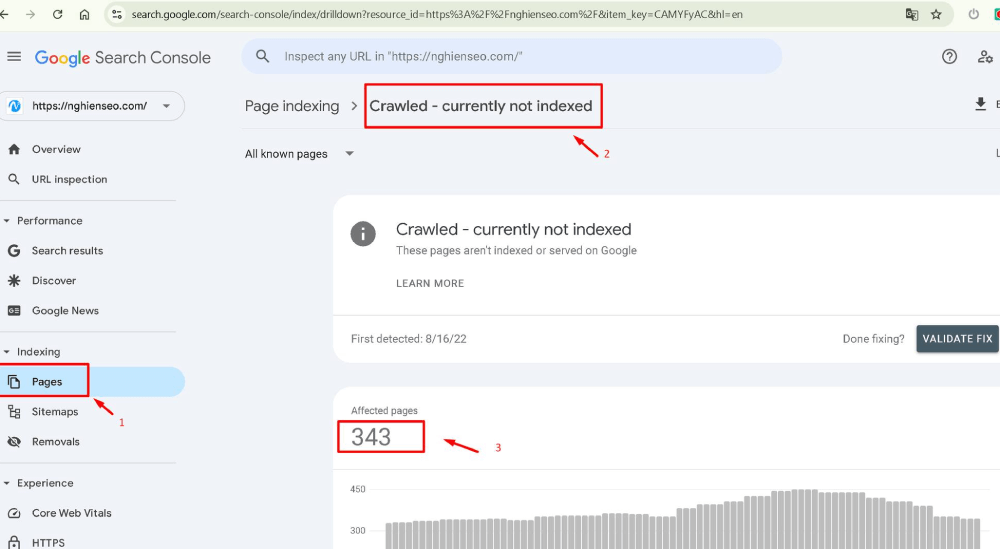
Phân tích toàn diện về “Crawled - Currently Not Indexed”
Hiểu về vấn đề
Khi Google thu thập dữ liệu một trang, nó truy cập và đọc nội dung để hiểu trang đó nói về gì. Tuy nhiên, không phải tất cả các trang đã thu thập dữ liệu đều được lập chỉ mục. Các lý do phổ biến bao gồm:
- Nội dung kém chất lượng hoặc mỏng (Thin content): Các trang có nội dung tối thiểu hoặc giá trị thấp có thể không được ưu tiên để lập chỉ mục.
- Nội dung trùng lặp: Nếu một trang là bản sao của trang khác, Google có thể chọn không lập chỉ mục để tránh dư thừa.
- Lỗi thu thập dữ liệu: Các vấn đề kỹ thuật như lỗi 404, lỗi máy chủ, hoặc chuyển hướng có thể ngăn chặn việc thu thập dữ liệu không đúng cách.
- Bị chặn bởi robots.txt hoặc thẻ meta: Nếu robots.txt chặn Googlebot hoặc trang có thẻ meta “noindex”, Google sẽ không lập chỉ mục.
- Liên kết nội bộ kém: Các trang không được liên kết tốt trong website có thể được coi là ít quan trọng (chưa nói tình trạng trang mồ côi).
- Trang mới hoặc vừa được cập nhật: Đôi khi, Google cần thời gian để xử lý và lập chỉ mục các trang mới hoặc được cập nhật.
Các bước để giải quyết “Crawled - Currently Not Indexed”
1. Đảm bảo chất lượng nội dung
- Sự độc đáo và giá trị: Đảm bảo nội dung là duy nhất và có giá trị cho người dùng.
- Tối ưu hóa từ khóa: Sử dụng từ khóa liên quan một cách tự nhiên trong tiêu đề, tiêu đề phụ, và văn bản.
- Cập nhật thường xuyên: Giữ nội dung tươi mới bằng cách cập nhật định kỳ.
- Đa dạng hóa định dạng: Kết hợp hình ảnh, video, và các phương tiện khác để nâng cao trải nghiệm người dùng.
2. Kiểm tra lỗi thu thập dữ liệu
- Sử dụng phần “Crawl” trong Google Search Console để xác định và sửa lỗi như 404.
- Kiểm tra website định kỳ bằng các công cụ như Screaming Frog.
3. Xác minh robots.txt và thẻ meta
- Đảm bảo robots.txt không chặn các trang quan trọng.
- Loại bỏ thẻ meta “noindex” từ các trang bạn muốn lập chỉ mục.
4. Cải thiện liên kết nội bộ
- Liên kết đến trang từ các phần liên quan khác của website.
- Đảm bảo navigation website rõ ràng và bao gồm các trang quan trọng.
- Duy trì sơ đồ website XML cập nhật và gửi qua Google Search Console.
5. Yêu cầu lập chỉ mục
- Sử dụng Công cụ Kiểm tra URL trong Google Search Console để yêu cầu lập chỉ mục.
- Lưu ý rằng việc này không đảm bảo lập chỉ mục nhưng ưu tiên thu thập dữ liệu.
6. Theo dõi và điều chỉnh
- Kiểm tra định kỳ báo cáo “Index Coverage” trong Google Search Console.
- Sử dụng Google Analytics để theo dõi sự cải thiện về lưu lượng truy cập.
- Điều chỉnh chiến lược dựa trên dữ liệu.
Xem xét bổ sung
Đối với website lớn (trên 10.000 trang), tập trung vào việc cải thiện liên kết nội bộ và chất lượng nội dung. Cập nhật thường xuyên để truyền tín hiệu cho Google rằng nội dung đang hoạt động và liên quan.
Vấn đề phổ biến và giải pháp
| Vấn đề | Giải pháp |
|---|---|
| Nội dung kém chất lượng hoặc mỏng (dạng thin content) | Cải thiện nội dung với thông tin chi tiết, duy nhất và từ khóa liên quan. |
| Nội dung trùng lặp | Sử dụng thẻ canonical hoặc tổng hợp các trang trùng lặp. |
| Lỗi thu thập dữ liệu (ví dụ, 404, 500) | Sửa liên kết hỏng, giải quyết lỗi máy chủ và gửi lại để thu thập dữ liệu. |
| Bị chặn bởi robots.txt hoặc thẻ meta | Điều chỉnh robots.txt và loại bỏ thẻ “noindex”. |
| Liên kết nội bộ kém | Thêm liên kết từ các trang liên quan và cập nhật sơ đồ website. |
| Trang mới hoặc vừa được cập nhật | Yêu cầu lập chỉ mục qua Công cụ Kiểm tra URL. |
Tóm lại
Sửa lỗi “Crawled - Currently Not Indexed” đòi hỏi một cách tiếp cận đa chiều, tập trung vào chất lượng nội dung, technical SEO, và tương tác tích cực với các công cụ của Google Search Console (GSC). Bằng cách đảm bảo nội dung chất lượng cao, giải quyết lỗi thu thập dữ liệu, xác minh quyền truy cập, cải thiện liên kết, yêu cầu lập chỉ mục, và theo dõi tiến trình, chủ website có thể tăng khả năng các trang được lập chỉ mục. Cập nhật và điều chỉnh định kỳ dựa trên dữ liệu có thể tối ưu hóa hơn nữa khả năng hiển thị và tăng thêm lưu lượng người dùng truy cập.
![]() Tài liệu tham khảo:
Tài liệu tham khảo:
[1]. How To Fix “Crawled – Currently Not Indexed” in GSC | Onely
[2]. What is ‘Crawled - currently not indexed’ in Search Console? Yoast
[3]. How to Fix “Crawled - Currently Not Indexed” Error in Google Search Console » Rank Math
[4]. How to Fix Crawled Currently Not Indexed - Search Console
#fixerror #fixCrawled #fixgooglesearchconsole #GoogleSearchConsole, SEO #CrawledNotIndexed, #LỗiCrawl, #YêuCầuChỉMục
![]() Cre by #NghienSEO (Team biên tập)
Cre by #NghienSEO (Team biên tập)