Chain-of-Thought (CoT) đã nổi lên như một phương pháp đột phá để tăng cường khả năng lý luận của Large Language Models (LLM), đặc biệt trong các tác vụ phức tạp đòi hỏi lý luận đa bước. Nghiên cứu khoa học “Demystifying Long Chain-of-Thought Reasoning in LLMs” đã làm sáng tỏ cách LLM phát triển khả năng lý luận mở rộng thông qua Supervised Fine-Tuning (SFT) và Reinforcement Learning (RL), nhấn mạnh tầm quan trọng của dữ liệu Long CoT. Bài viết này tổng hợp các nguyên tắc cốt lõi từ nghiên cứu này và các nguồn khác để cung cấp hướng dẫn toàn diện về cách tạo Long CoT hiệu quả.
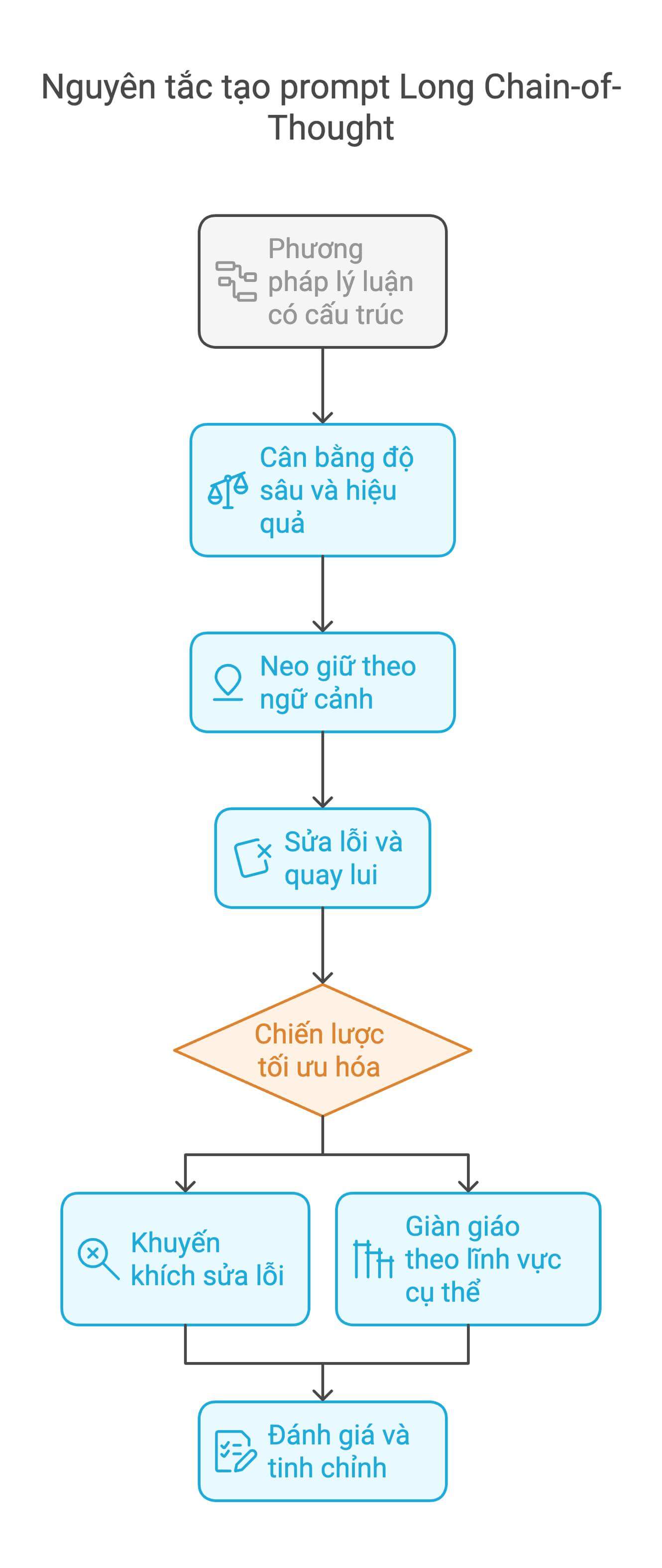
1. Phương pháp reasoning có cấu trúc
- Phân tích từng bước (Step-by-Step Breakdown): Khuyến khích mô hình tạo ra các bước reasoning trung gian, bắt chước quá trình giải quyết vấn đề của con người. Điều này đặc biệt quan trọng đối với Long CoT, nơi các bước reasoning chi tiết và tuần tự tạo nên sức mạnh của nó.
Ví dụ về prompt:
Giải quyết vấn đề này từng bước: [vấn đề]. Đầu tiên, phân tích thông tin đã cho. Thứ hai, áp dụng các công thức liên quan. Thứ ba, xác thực giải pháp.
2. Cân bằng độ sâu và hiệu quả
-
Khen thưởng tính đúng đắn và ngắn gọn (Rewarding Correctness and Brevity): Sử dụng các cụm từ như *“Giải thích ngắn gọn trong 5–7 bước”*để tránh dài dòng trong khi vẫn duy trì độ sâu lý luận. Long CoT không đồng nghĩa với việc nói lan man; đúng hơn, đó là cung cấp đủ các bước chi tiết cần thiết cho lý luận mạnh mẽ.
-
Tránh dư thừa (Avoid Redundancy): Bao gồm các hướng dẫn để tránh logic lặp đi lặp lại trong nhiều bước. Prompt nên khuyến khích sự tiến triển logic tuyến tính và hiệu quả.
3. Neo giữ theo ngữ cảnh (Contextual Anchoring)
- Tập trung vào lĩnh vực (Domain Focus): Duy trì sự liên quan của chủ đề bằng các cụm từ như “Giữ trong phạm vi [domain]” để tránh lạc đề. Đặc biệt khi CoT được mở rộng, việc duy trì ngữ cảnh là rất quan trọng để đảm bảo mô hình không đi lệch hướng.
Ví dụ về phân tích pháp lý (Legal Analysis):
Phân tích điều khoản hợp đồng này. Tập trung vào nghĩa vụ, trách nhiệm pháp lý và điều kiện chấm dứt. So sánh từng yếu tố với thông lệ ngành tiêu chuẩn.
4. Sửa lỗi và quay lui (Error Correction and Backtracking)
- Khuyến khích tự sửa lỗi (Incentivize Self-Correction): Hướng dẫn mô hình xác định và sửa các lỗi tiềm ẩn trong lý luận của nó. Đây là một khả năng tiềm ẩn đáng kể được phát hiện trong các mô hình cơ sở và prompt có thể khai thác khả năng này.
Ví dụ:
Nếu bất kỳ bước nào chứa đựng sự không nhất quán, hãy quay lại (backtrack) và đề xuất các phương pháp thay thế.
5. Chiến lược prompt kết hợp (Hybrid Prompting Strategies)
- Kết hợp CoT với các kỹ thuật khác: Sử dụng kết hợp với Retrieval-Augmented Generation (RAG) để tăng cường nền tảng thực tế hoặc zero-shot CoT cho các tác vụ mới. RAG đặc biệt có lợi cho Long CoT khi cần thiết phải truy cập và tích hợp thông tin bên ngoài trong suốt quá trình lý luận đa bước.
Ví dụ:
Sử dụng [tài liệu được cung cấp], phác thảo các bước để định cấu hình [tính năng phần mềm]. Trích dẫn các phần liên quan trong mỗi bước.
6. Chiến lược tối ưu hóa (Optimization Strategies)
-
Kiểm soát độ dài (Length Control): Sử dụng các từ bổ nghĩa như “Giải thích ngắn gọn trong 5-7 bước” để quản lý tính dài dòng và đảm bảo CoT không trở nên dài dòng không cần thiết.
-
Lấy mẫu ngẫu nhiên (Stochastic Sampling): Điều chỉnh các tham số (ví dụ: temperature) để khám phá các đường dẫn lý luận đa dạng trước khi hội tụ. Điều này có thể giúp khám phá các giải pháp sáng tạo hơn trong Long CoT.
Nguyên tắc nâng cao: Khuyến khích sửa lỗi (Error Correction Incentives) và giàn giáo theo lĩnh vực cụ thể (Domain-Specific Scaffolding)
Khuyến khích sửa lỗi (Error Correction Incentives)
Hướng dẫn mô hình tự xác định lỗi sai:
Nếu bất kỳ bước nào chứa đựng sự không nhất quán, hãy quay lại (backtrack) và đề xuất các phương pháp thay thế.
Ví dụ:
Giải phương trình 3x + 5 = 20. Sau mỗi bước, hãy kiểm tra xem phép toán có phù hợp với các quy tắc đại số hay không.
Giàn giáo theo lĩnh vực cụ thể (Domain-Specific Scaffolding)
Đối với các nhiệm vụ STEM:
1. Parse problem constraints 2. Identify applicable theorems/formulas 3. Execute calculations 4. Validate against edge cases
Đối với Viết sáng tạo (Creative Writing): “Phát triển động cơ của nhân vật chính trong ba giai đoạn: childhood influences, pivotal life events, và current goals.”
Đánh giá và tinh chỉnh (Evaluation and Refinement)
Kiểm tra tính hợp lệ (Validity Checks):
Sau khi đưa ra giải pháp, hãy liệt kê ba sai sót tiềm ẩn trong lý luận này.
Phân tích so sánh (Comparative Analysis):
Tạo hai phương pháp tiếp cận riêng biệt cho vấn đề này, sau đó đánh giá phương pháp nào hiệu quả hơn.
Ví dụ thực tế
Prompt:
`Lập kế hoạch hệ thống giao thông đô thị bền vững cho một thành phố 2 triệu dân. Cơ cấu phản hồi của bạn như sau:
- Đánh giá nhu cầu (commuter patterns, existing infrastructure)
- Lựa chọn công nghệ (ưu tiên emissions reduction)
- Giai đoạn thực hiện
- Phân tích chi phí-lợi ích (Cost-benefit analysis)
Bao gồm các điểm quay lui (backtracking points) nơi các giả định có thể thất bại.`
Kết
Những nguyên tắc này giúp tận dụng khả năng của LLM để lý luận có cấu trúc, nâng cao hiệu suất của chúng trong các tác vụ phức tạp bằng cách khuyến khích các quy trình giải quyết vấn đề chi tiết, từng bước. Long CoT là chìa khóa để mở khóa khả năng lý luận mạnh mẽ của LLM. Bằng cách áp dụng các nguyên tắc này, bạn có thể tạo ra các prompt Long CoT hiệu quả, cho phép LLM giải quyết các vấn đề phức tạp một cách thông minh và đáng tin cậy hơn.
Bài của facebook Frank T. Bergmann (Group Bình dân học AI)