PANDU NAYAK NÓI GÌ VỀ THUẬT TOÁN XẾP HẠNG GOOGLE
A. PANDU NAYAK LÀ AI?
Năm 2023, Pandu Nayak là Phó chủ tịch bộ phận tìm kiếm (Vice President In Search), một trong những nhân vật quyền lực nhất Google.
Pandu Nayak sinh ra ở Ấn Độ, sau khi tốt nghiệp trường đại học kỹ thuật hàng đầu ở quê hương, ông qua Mỹ học PhD Khoa học máy tính ở Standford, rồi làm R&D các dự án trí tuệ nhân tạo của NASA.
Tới năm 2013, ông đã làm việc cho Google 18 năm, là người dẫn dắt team thuật toán và xếp hạng của Google (algorithmic and ranking), đặc biệt là áp dụng phân tích ngôn ngữ tự nhiên vào kết quả tìm kiếm.
Hiểu nôm na, nếu Danny Sullivan chuyên phụ trách quan hệ công chúng, John Mueller và Gary Illyes làm truyền thông và educate thị trường cho Google.
Thì Pandu Nayak chính là CHIẾN TƯỚNG, đảm nhận xây dựng các thuật toán xếp hạng cho Google Search.
Vào tháng 10/2023, trong phiên tòa chống độc quyền Google ở Mỹ, Pandu Nayak là người đầu tiên của Google làm chứng về cách hoạt động của Google Search.
Trong phiên điều trình, Pandu Nayak đã trình bày cách Google hoạt động, bao gồm từ việc lập chỉ mục, trích xuất dữ liệu, đo lường dữ liệu người dùng, các mô hình xếp hạng lõi(core system) và học sâu (deep learning system), vai trò bộ phận đánh giá chất lượng tìm kiếm, và nhiều yếu tố quan trọng khác.
Những thông tin này với anh em SEOer, là cực kỳ quan trọng, để bạn hiểu cơ chế hoạt động thực sự của Google Search.
B. QUÁ TRÌNH TRÍCH XUẤT DỮ LIỆU CỦA GOOGLE
Tính tới năm 2020, hệ thống Google có thể index tới 400 tỷ kết quả, một khối lượng dữ liệu siêu khổng lồ.
Khi bạn search một từ khóa, hệ thống của Google có tới hàng triệu kết quả KHỚP với truy vấn đó.
Bài toán là Google cần hiển thị kết quả liên quan và chất lượng nhất ứng với truy vấn người dùng, với chi phí thấp nhất, và nhanh nhất có thể.
Để làm điều này, Google dùng hàng trăm THUẬT TOÁN và mô hình HỌC MÁY, để trích xuất những kết quả tốt nhất.
Google có thể sử dụng khoảng 100 tín hiệu xếp hạng, bao gồm những thuật toán quen thuộc như PageRank, BERT, RankBrain, Helpful Content System…, và nhiều yếu tố quan trọng khác mà anh em chưa từng nghe tới.
Tín hiệu quan trọng nhất, đối với hệ thống trích xuất dữ liệu như Google, chính là BẢN THÂN TÀI LIỆU đó (document itsefs).
Ngoài ra, còn có các tín hiệu quan trọng khác (key signal) như Topicality, Page Quality, Reliability, Localization và Navboost.
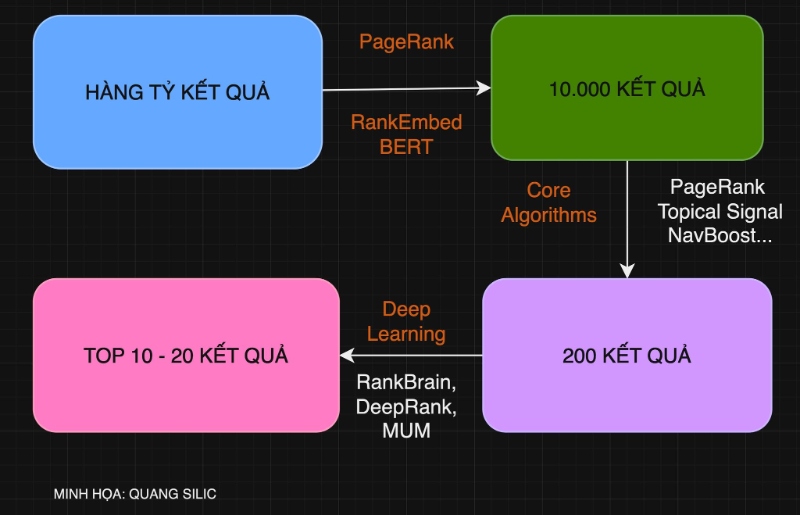
Quá trình truy xuất (retrieval process), theo Quang, có thể chia làm 3 giai đoạn chính:
Giai đoạn 1: Với mỗi truy vấn, Google dùng PageRank + RankEmbed BERT để sắp xếp và trích xuất dữ liệu, để có được khoảng 10.000 kết quả liên quan nhất.
Giai đoạn 2: Từ khoảng 10.000 kết quả, Google dùng thuật toán lõi (core algorithms), để cắt tỉa còn khoảng 200 kết quả. Mỗi kết quả được Google tính điểm số (scrore). Một trong những tín hiệu quan trọng là NAVBOOST, thuật toán đo lường dữ liệu người dùng (user data).
Giai đoạn 3: Từ 200 kết quả, Google bắt đầu áp dụng mô hình học sâu (deep learning), để tự động điều chỉnh vị trí xếp hạng (initial ranking / score) cho từng kết quả.
Trong ba giai đoạn đó, Google vừa sử dụng mô hình truyền thống (core algorithm), và các mô hình trí tuệ nhân tạo (deep learning) để xếp hạng vị trí từ khóa.
C. GIAI ĐOẠN 1: TRÍCH XUẤT DỮ LIỆU (TỪ HÀNG TỈ KẾT QUẢ => 10.000 KẾT QUẢ)
Khi bạn search một cụm từ tìm kiếm, ví dụ XE MÁY HONDA, hệ thống index Google có thể có tới 10 triệu kết quả khớp (maching) với truy vấn đó.
Vậy Google xử lý thế nào?
Google sẽ tìm trong kho siêu dữ liệu (gần 400 tỷ kết quả), những tài liệu liên quan tới XE MÁY HONDA.
Nhưng lục tung cả tỷ tài liệu để tìm kiếm là chuyện gần như không thể, vì chi phí quá lớn và thời gian chờ quá lâu, nên Google cần có SỰ ƯU TIÊN nào đó, để tìm được những trang sự liên quan với chất lượng cao nhất.
Google làm bằng cách nào?
Google sẽ tính điểm PageRank cho từng tài liệu. Đây là thuật toán lõi Google từ thời sơ khai, và chi phí tài nguyên để tính toán PageRank cho từng page là rất thấp, vì đây chỉ là công thức toán học đơn giản.
Google sẽ đi dò từ đầu xuống cuối danh sách, theo sức mạnh PageRank giảm dần, các tài liệu liên quan tới XE MÁY HONDA, khi đạt tới một số lượng vừa đủ để đảm bảo CHẤT LƯỢNG, khoảng 10,000 tài liệu, thì Google dừng lại.
Đây chính là cách xếp hạng nguyên thủy của Google.
ỨNG DỤNG VỚI NGƯỜI LÀM SEO
- NỘI DUNG
Nội dung của bạn BẮT BUỘC liên quan tới truy vấn người dùng, nếu không thì trang của bạn có mạnh tới đâu, Google cũng bó tay (the document itself is perhaps the most important thing).
Cách tốt nhất là bạn cần xây dựng nội dung về chủ đề đó, và được tối ưu SEO cơ bản.
Một cách làm Quang thấy dễ và hiệu quả nhất, là bạn đưa từ khóa vào những VỊ TRÍ QUAN TRỌNG NHẤT trong bài viết (như ở tiêu đề, các thẻ H, tăng mật độ từ khóa chính cao hơn các từ ngữ khác).
- SEO CÁC NHÓM TỪ KHÓA CÓ ĐỘ CẠNH TRANH KHÁC NHAU
Những từ khóa cạnh tranh thấp (easy keyword), là những từ khóa liên quan tới CHỦ ĐỀ MỚI (chưa từng xuất hiện trên internet), hoặc từng xuất hiện trên internet nhưng QUÁ ÍT trang web nói tới. Khi đó, PageSEO của bạn dễ dàng lọt vào TOP 10.000 kết quả đầu tiên của Google.
Về mặt kỹ thuật, toán tử ALL-IN-TITLE là cách tìm được nhóm từ khóa này, hoặc bạn cần nhanh nhạy để bắt TREND trên nền tảng social (Facebook, Tiktok, Instagram…).
Ngược lại, với chủ đề mà Google thừa mứa dữ liệu, bạn cần tăng điểm số PageRank, bằng cách xây dựng backlink chất lượng cho trang, để PageSEO lọt vào khoảng 10.000 kết quả đầu tiên, qua được vòng sát hạch của Google.
D. GIAI ĐOẠN 2: TỪ 10.000 KẾT QUẢ => 200 KẾT QUẢ (DỰA VÀO THUẬT TOÁN LÕI CORE ALGORITHMS)
Thời điểm này, Google dùng các THUẬT TOÁN LÕI để xếp hạng.
Thuật toán lõi (core algorithms) tính điểm xếp hạng ban đầu (initial ranking / score) cho mỗi tài liệu, sau đó Google sắp xếp các trang theo điểm số từ cao xuống thấp, và hiển thị cho người dùng.
Điểm số này viết tắt là IR score (Information Retrieval).
Những thuật toán lõi bao gồm PageRank, Topical Signal, NavBoost, các yếu tố về vị trí và thiết bị người dùng.
Trong các yếu tố trên, NAVBOOST, thuật toán xếp hạng dựa trên dữ liệu người dùng, được khẳng định là một yếu tố xếp hạng QUAN TRỌNG.
Pandu Nayak nói “ Navboost is one of the important signnals”.
- NAVBOOST
Navboost được training dựa trên dữ liệu người dùng (user data) từ 2005.
Navboost có thể thu thập được những dữ liệu sau:
-
Những từ khóa người dùng tìm kiếm, và số lần họ tìm kiếm từ khóa đó (chính là Volume Search)
-
Hành vi người dùng khi nhấp chuột, bao gồm CTR (tỷ lệ nhấp chuột), dwell time (thời gian người dùng trên trang), hành vi của người dùng sau khi vào trang, hoặc họ quay lại thanh tìm kiếm (bad click), hoặc tiếp tục hành trình trên trang web (good click)
-
Nền tảng người dùng tìm kiếm, là mobile hay desktop
-
Vị trí tìm kiếm, đâu là vị trí địa lý có nhiều người dùng tìm kiếm từ khóa nhất
Navboost có thể lưu trữ thông tin người dùng liên tục tới 13 tháng (tính từ năm 2017).
GLUE, là một tên gọi khác của Navboost.
Trong khi Navboost chỉ đo lường được dữ liệu người dùng từ kết quả tự nhiên (SEO), GLUE đo được trải nghiệm người dùng trên tất cả các định dạng còn lại trên SERP, bao gồm cả Google Adword, Google Map, hình ảnh, biểu đồ tri thức Knowledge Graph…
NavBoost sinh ra theo mô hình hai chiều, vừa giúp Google PHỤC VỤ người dùng, vừa HỌC HỎI từ người dùng để nâng cao chất lượng tìm kiếm.
- ỨNG DỤNG VỚI NGƯỜI LÀM SEO
Khi PageSEO qua vòng gửi xe 10.000 domain, bạn cần tối ưu cho cả Google (machine) lẫn người dùng (human).
Có thể tách làm hai giai đoạn chính: TRƯỚC và SAU khi có người dùng vào PageSEO.
Giai đoạn khi PageSEO chưa có người dùng truy cập (ví dụ TOP 30), bạn cần tối ưu yếu tố chỉ cho Googlebot đọc, chẳng hạn như backlink (PageRank), chủ đề liên quan (Signal), xây dựng nội dung phù hợp với vị trí (local) và thiết bị của người dùng.
Tuy nhiên, khi đã có người dùng truy cập PageSEO (TOP 20 - 30), Navboost sẽ đo được dữ liệu người dùng (user data).
Lúc này, bạn cần đem lại cho người dùng TRẢI NGHIỆM TỐT NHẤT có thể.
Tại Việt Nam có hai trường phái tối ưu cho giai đoạn này:
CÁCH 1: CHẠY TRAFFIC USER
Một số bên chạy traffic user để thao túng kết quả Google.
Ưu điểm là nó hoàn toàn đáp ứng yêu cầu kỹ thuật về mặt thuật toán Google.
Nhưng nhược điểm đó là tín hiệu giả, người dùng vào từ traffic user không phải KHÁCH HÀNG TIỀM NĂNG, từ đó đó việc phân tích hành vi, xây dựng phễu khách hàng, chăm sóc và chạy quảng cáo re-marketing sẽ sai be bét.
Ngoài ra, traffic user được bơm từ BÊN NGOÀI vào, chứ không được sản sinh từ NỘI LỰC của trang web, nên bạn cần duy trì liên tục. Nó mang tính ngắn hạn, hết thuốc là bạn lên đường.
Traffic user có thể đến từ các nguồn rủi ro cao như 18+, download phần mềm c.r.a.c.k…, khiến các bên cung cấp dễ dính lao lý.
Đồng thời nó mang tính thủ thuật blackhat, nên làm giảm uy tín cho doanh nghiệp lớn triển khai SEO theo hướng này.
CÁCH 2: XÂY DỰNG TRẢI NGHIỆM CHO KHÁCH HÀNG THẬT SỰ
Về mặt whitehat và chiến lược dài hạn, bạn cần xây dựng được trải nghiệm tốt cho KHÁCH HÀNG THẬT SỰ CỦA MÌNH, từ góc độ kỹ thuật (tốc độ), chất lượng nội dung (content), tính mượt mà và dễ dùng của trang web(UX - UI), cao hơn nữa là sự khác biệt và lợi thế cạnh tranh (USP) của chính doanh nghiệp bạn.
Tại Việt Nam, Quang thấy MONA MEDIA có case study rất thành công cho cách làm này, khi họ ranking được hai keyword “dịch vụ SEO” và “thiết kế web" có độ cạnh tranh rất cao trong ngành, và ranking bền vững.
Ở nước ngoài, BacklinkO là danh bất hư truyền với trường phái này.
Bạn có thể tham khảo.
E. GIAI ĐOẠN 3: TỰ ĐỘNG ĐIỀU CHỈNH VỊ TRÍ TỪ KHÓA 200 KẾT QUẢ ĐẦU TIÊN BẰNG DEEP LEARNING
Từ 2015, Google bắt đầu dùng mô hình học sâu (deep learning) trong xếp hạng từ khóa, bao gồm RankBrain, DeepRank, RankEmbed BERT, và mô hình mới và mạnh nhất hiện tại là MUM (Multitask Unified Model).
Các mô hình này cực mạnh, nhưng chi phí vận hành quá cao, độ trễ lớn, và tồn tại các vấn đề liên quan tới quản trị rủi ro.
Nên Google chủ yếu dùng chúng cho tập dữ liệu nhỏ, và ĐIỀU CHỈNH VỊ TRÍ XẾP HẠNG, chứ không áp dụng cho toàn bộ quá trình xếp hạng.
Pandu Nayak bàn luận về 3 mô hình học sâu mà Google dùng, đó là RankBrain, DeepRank và RankEmbed.
Cả ba mô hình này đều được training dựa vào truy vấn, lượt click và trải nghiệm người dùng (user).
- RANKBRAIN
RankBrain có thể TỰ ĐỘNG ĐIỀU CHỈNH vị trí từ khóa của TOP 20 - TOP 30 trên SERP, mà không cần sự can thiệp của yếu tố con người (các kỹ sư của Google).
Nói cách khác, RankBrain là mô hình trí tuệ nhân tạo có thể TỰ HỌC(deep learning) và TỰ RA QUYẾT ĐỊNH, mà con người không cần hoặc không thể can thiệp.
Huấn luyện RankBrain tốn nhiều chi phí hơn so với các thuật toán xếp hạng khác, nên Google chỉ áp dụng cho TOP 20 - 30, chứ chưa không áp dụng cho hàng trăm hoặc ngàn kết quả.
RankBrain được training trên tất cả các ngôn ngữ (tiếng Anh, và tất nhiên cả tiếng Việt), dựa trên dữ liệu người dùng trong vòng 13 tháng liên tục như NavBoost.
Sau đó được tinh chỉnh (fine-tuned) dựa trên tập dữ liệu chuẩn của bộ phận rater (là con người), và thường xuyên được training lại với data mới nhất.
- DEEPRANK
Mô hình xử lý ngôn ngữ tự nhiên tiên tiến nhất của Google: BERT.
Khi đưa vào quá trình xếp hạng từ khóa, BERT sẽ trở thành DeepRank.
DeepRank mạnh mẽ hơn RankBrain, được training trên dữ liệu người dùng, tinh chỉnh trên data chuẩn của rater, có khả năng xử lý ngôn ngữ tự nhiên (NLP) cực kỳ mạnh mẽ.
Để xếp hạng từ khóa, DeepRank cần 2 khả năng: hiểu ngôn ngữ và có được kiến thức chung về thế giới thực tế (world knowledge).
Hạn chế của DeepRank, là nó chỉ có khả năng xử lý ngôn ngữ, chứ chưa có đủ kiến thức thực tế về thế giới (world knowledge).
Mặc dù DeepRank học được rất nhiều kiến thức từ môi trường internet (như ChatGPT, Google Bard…) , nhưng có những kiến thức về thế giới thực tế chưa có trên internet, nên Google phải tìm cách xử lý khác.
Cả DeepRank và RankBrain đều có khả năng xếp hạng vị trí từ khóa.
Tuy nhiên DeepRank là BERT, nên có thể đọc hiểu tốt ngôn ngữ (hiểu được ngôn ngữ, từ đó có thể đóng vai trò quan trọng trong xếp hạng).
Còn RankBrain thì không, RankBrain có thể điều chỉnh tự động vị trí xếp hạng của TOP 20 - TOP 30 dựa trên trải nghiệm người dùng, còn khả năng phân tích ngôn ngữ còn nhiều hạn chế.
DeepRank không thể thay thế cho RankBrain, mà chúng có vai trò bổ sung cho nhau (complementary strenghs).
- RANKEMBED VÀ MUM
RankEmbed được triển khai từ trước khi có BERT, và trở thành RankEmbed BERT khi áp dụng vào quá trình xếp hạng.
RankEmbed BERT có khả năng xử lý tốt ngôn ngữ, được huấn luyện trên cả TÀI LIỆU (điểm khác biệt), dữ liệu người dùng, sau đó tinh chỉnh bằng data chuẩn của rater.
RankEmbed BERT có thể bổ sung thêm những kết quả mà trong quá trình trích xuất dữ liệu, các thuật toán truyền thống không thể tìm thấy (GIAI ĐOẠN 1).
MUM (Multitask Unified Model) là một trong những mô hình deep learning mạnh nhất của Google hiện tại, có năng lực xử lý dữ liệu mạnh gấp 1.000 lần BERT, nhưng mô hình này quá lớn và quá chậm.
Do đó, Google ưu tiên dùng những mô hình nhỏ hơn để phục vụ cho những mục tiêu cụ thể, như các thuật toán liên quan tới bộ lọc (classifier) như nhận dạng nội dung spam hay helpful content.
F. ĐÁNH GIÁ KẾT QUẢ XẾP HẠNG SERP TỪ PHÍA CON NGƯỜI VÀ NGƯỜI DÙNG
Nếu các công ty GAME LỚN luôn có bộ phận Game Tester, làm nhiệm vụ chơi thử và xác định lỗi game trước khi tung ra thị trường.
Thì Google cũng có bộ phận Tester cho kết quả tìm kiếm, được gọi là bộ phận Search Quality Rater, bao gồm 16.000 nhân viên trên toàn thế giới.
Bộ phận này đánh giá chất lượng tìm kiếm của Google theo guideline vô cùng chặt chẽ (tiêu chuẩn EEAT cũng từ bộ guideline này).
Họ sẽ tính điểm chất lượng cho từng kết quả, gọi là IS Score (Information Satisfaction Score).
IS Score sẽ được sử dụng làm dữ liệu đầu vào, để training các mô hình học máy của Google như RankBrain, DeepRank, RankEmbed BERT, MUM…
Ngoài ra, Google có thể sử dụng bộ phận rater để kiểm nghiệm (experiment) chất lượng tìm kiếm một cách nhanh chóng khi có sự biến động lớn về vị trí từ khóa, đặc biệt khi Google cập nhật các thuật toán lõi (core update), để đội ngũ kỹ sư Google xử lý nhanh vấn đề phát sinh.
Một thông tin thú vị nữa là bộ phận rater thực thi công việc trên THIẾT BỊ DI ĐỘNG, chứng tỏ Google đang ưu tiên moblie-first-ranking ở mức độ rất cao.
Tuy nhiên, Google gặp phải những vấn đề đối với human rater, đó là bộ phận testing có thể gặp vấn đề với những câu hỏi quá chuyên sâu về kỹ thuật (technical queries), họ không đại diện cho số đông, và không phải lúc nào họ cũng đủ nhận thức để đánh giá thêm các yếu tố về sự mới mẻ (freshness) và ngữ cảnh từ góc độ của người dùng thực sự.
Vậy thì làm sao để khắc phục được điều này, vì data từ rater không đủ LỚN và CHÍNH XÁC để giúp Google xếp hạng từ khóa?
Đó là học hỏi từ NGƯỜI DÙNG qua dữ liệu NHẤP CHUỘT (CLICK).
Google sẽ ghi nhớ (memorizing), hơn là hiểu (understanding) dữ liệu nhấp chuột của người dùng.
Từ việc ghi nhớ dữ liệu lớn (Google nhận khoảng hơn 1 triệu truy vấn mỗi ngày), Google có thể dự đoán được ý định tìm kiếm của những người dùng mới, và hiển thị kết quả phù hợp nhất với họ.
Train on the past, predict the future.
ỨNG DỤNG VỚI NGƯỜI LÀM SEO
RankBrain, và đặc biệt là DeepRank, có khả năng xử lý ngôn ngữ tự nhiên (NLP) cực tốt, để giúp Google giảm dần phụ thuộc vào data người dùng.
Do đó, bạn cần viết nội dung cho con người, chứ không cần quá tập trung cho Google.
Cách viết nội dung kiểu xôi thịt ngày xưa, như nhồi nhét từ khóa, bắt buộc in đậm in nghiêng từ khóa, đoạn đầu đoạn cuối bài viết phải có từ khóa… đã trở nên lỗi thời.
Thay vào đó, bạn cần viết tự nhiên theo chính văn phong của mình, phù hợp với bối cảnh (context), và giải quyết được vấn đề của khách hàng.
Ngoài ra, việc các thuật toán RankBrain / DeepRank vẫn được training từ trải nghiệm người dùng như NavBoost, nên việc tạo trải nghiệm tốt cho người dùng vẫn là kim chỉ nam cho nội dung của bạn.
Bản ghi phiên điều trần của Mr. Pandu Nayak trước Tòa án Mỹ cho bạn tham khảo nhé: thecapitolforum.com/wp-content/uploads/2023/10/101823-USA-v-Google-PM.pdf
Chúc bạn thành công !!!